
Introducing the latest article in our Data Deep Dive series, Searching for Meaning with LangChain
Written by NICD Data Scientists Dr Fergus McClean, Dr Mac Misiura, and Dr Jordan Connolly

Introduction
Have you ever been searching for something, but you don't know exactly what? Or you know what to search for but it's called something slightly different in the document you're looking for? Maybe you would like to search for a category, like dogs, and find examples of terms in that category, like golden retriever.
These kinds of searches are well suited to semantic search. This type of search tries to match the meaning of your query to the meaning of words in some bank of documents. Most popular search engines use this technique to give you better results. Semantic search is usually based on an approach called vector search.
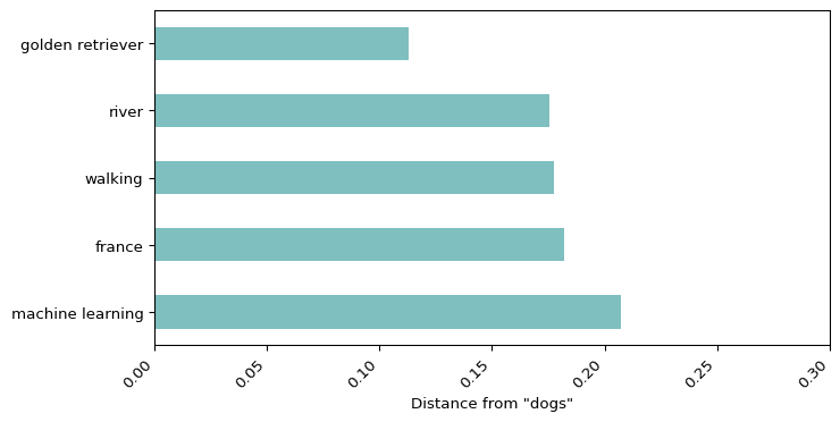
Vector search takes your query, e.g. "dogs", and turns it into a numerical representation, known as an embedding. The first ten numbers from an embedding of "dogs" are shown below. The complete version has 384 numbers, but this differs depending on how the translation is done. To easily go from text, to searchable embeddings, we will use a framework called LangChain.
from langchain.embeddings import HuggingFaceBgeEmbeddings
import matplotlib.pyplot as plt
import pandas as pd
embeddings = HuggingFaceBgeEmbeddings(
model_name='BAAI/bge-small-en',
model_kwargs={"device": "cpu"}
)
dog = embeddings.embed_documents(['dogs'])[0]
print(", ".join([str(d) for d in dog[:10]]))
-0.0376073457300663, -0.06360463798046112, 0.019663244485855103, -0.009882763028144836, 0.009240113198757172, 0.01943262107670307, 0.006302166264504194, 0.012383431196212769, 0.01129855029284954, 0.024781595915555954
This group of numbers is then compared to the groups of numbers that represent some other set of words or documents. The distances are calculated between your search term and the items you are searching for. Shorter distances equate to more similarity in meaning. Therefore, the best results are the ones which are least far away from your search term.
from langchain.evaluation import load_evaluator
evaluator = load_evaluator("embedding_distance", embeddings=embeddings)
words = ["walking", "france", "golden retriever", "river", "machine learning"]
scores = [
evaluator.evaluate_strings(prediction="dogs", reference=word)["score"]
for word in words
]
df = pd.DataFrame({"words": words, "scores": scores})
df = df.sort_values("scores", ascending=False)
df.plot.barh(x="words", xlabel='Distance from "dogs"', legend=False, ylabel='', color='teal', figsize=(8,4), alpha=0.5)
_ = plt.xticks(rotation=45, ha="right")
_ = plt.xlim(0, 0.3)
Models
You are probably at this point wondering how the magic transformation from words into numbers is done. In the case above, we used a model called BGE Small. BGE is short for BAAI general embedding. BAAI stands for Beijing Academy of Artificial Intelligence. But, what's an embedding? This is just another word for the numbers that represent the meaning of the text. Embeddings are very powerful and can represent all kinds of media, not just text.
Other models are available and there is a leaderboard on Hugging Face that you can check out. We went for BGE Small because it works quite well for a relatively small model and number of dimensions (numbers). There is a classic trade-off between model size and quality of output so you may want to use a larger model.
Data
We will use a freely available dataset of CNN and Daily Mail news articles which is available on Hugging Face. To reduce the number of documents, we will only use the training set, which is made up of 11,490 documents. To reduce the size of each document, we will only use the highlights, and not the full articles.
from datasets import load_dataset
DATASET = "cnn_dailymail"
dataset = load_dataset(DATASET, "3.0.0", split='test')['highlights']
for i, t in enumerate(dataset[:5], 1):
print(f"{i}) {t}")
1) Membership gives the ICC jurisdiction over alleged crimes committed in Palestinian territories since last June. Israel and the United States opposed the move, which could open the door to war crime investigations against Israelis.
2) Theia, a bully breed mix, was apparently hit by a car, whacked with a hammer and buried in a field. “She’s a true miracle dog and she deserves a good life,” says Sara Mellado, who is looking for a home for Theia.
3) Mohammad Javad Zarif has spent more time with John Kerry than any other foreign minister. He once participated in a takeover of the Iranian Consulate in San Francisco. The Iranian foreign minister tweets in English.
4) 17 Americans were exposed to the Ebola virus while in Sierra Leone in March. Another person was diagnosed with the disease and taken to hospital in Maryland. The National Institutes of Health says the patient is in fair condition after weeks of treatment.
5) Student is no longer on Duke University campus and will face disciplinary review. School officials identified student during investigation and the person admitted to hanging the noose, Duke says. The noose, made of rope, was discovered on campus about 2 a.m.
Chunking
It's possible to create an embedding of the entire document. This may work well for very small documents. However, when working with larger documents, it's a good idea to split your document into chunks, each with its own embedding. This will result in more useful search results when querying your embeddings. There are a variety of ways to split documents into chunks.
- Character Splitting
- Recursive Character Text Splitting
- Document Specific Splitting
- Semantic Splitting
- Agentic Splitting
A detailed overview of each method is available here. When choosing between the methods, you may want to consider:
1) The size of your documents
2) The embedding model you're using
3) The queries you will make
4) How you will use the results
We will use the recursive character splitter within LangChain because it works well for generic text. Overlapping chunks is a good idea to make sure that phrases stay together.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=30, chunk_overlap=10)
documents = text_splitter.create_documents(dataset)
for i, d in enumerate(documents[:5], 1):
print(f"{i}) {d.page_content}")
1) Membership gives the ICC
2) the ICC jurisdiction over
3) over alleged crimes committed
4) committed in Palestinian
5) territories since last June.
Vector Databases
Once you've created all your wonderful embeddings, it would be handy to be able to put these somewhere that they can be easily accessed. That place is called a vector database. The key functionality of a vector database is that it provides the ability to search for embeddings based on their proximity to other embeddings. There are many different types of vector database out there. We will be using one called chroma. Other options include FAISS, LanceDB and pgvector. LangChain provides a simple interface to vector databases, which allows you to embed and insert your documents in a single step.
from langchain_community.vectorstores import Chroma
import os
persist_directory = 'bge-small'
if not os.path.exists(persist_directory):
db = Chroma.from_documents(documents, persist_directory=persist_directory, collection_name=DATASET, embedding=embeddings)
else:
db = Chroma(persist_directory=persist_directory, collection_name=DATASET, embedding_function=embeddings)
Search interface
The next step is the main bit but also the simplest bit - searching for documents. LangChain makes this embarrassingly easy. All you need to do is provide a query, and the number of nearest documents to return (k). Under the hood, LangChain is embedding your query, and then using cosine similarity to compare its embeddings with all those in your database. Depending on the model you are using, the query may need to be of a similar length to the embedded documents (symmetric). Searching for nearby embeddings is very fast and could be done after a user enters a query in a search box. However, having a very high number of documents in your database may slow things down. If your search takes too long, it might be time to look at some indexing approaches which cluster your documents and improve the efficiency of searches.
query = "golden retriever"
results = db.similarity_search(query, k=10)
for i, r in enumerate(results):
print(f'{i+1}) {r.page_content}')
1) found the golden retriever
2) Retriever from California has
3) Fritz the Golden Retriever
4) dog was more important to
5) about the pet’s injuries.
6) Dogs charity hailed the study
7) return of seven-year-old dog
8) treats, a new study claims.
9) Dog was discovered in play
10) Owner decided pet pooch
You could easily build a prototype search application using Streamlit like this:
import streamlit as st
search = st.text_input("search", value="golden retriever")
for i, r in enumerate(db.similarity_search(search, k=10)):
st.write(f'{i+1}) {r.page_content}')
Re-ranking
Can we do better? It turns out there's a final step you can take to further improve the results of your semantic search, and it's called reranking (not a real word yet, we checked). We used a quick method to search across all our documents, but it's not the best method available. There is a more accurate but slower method called cross-encoding. In this approach, we take two sentences and feed them both into the model to produce a similarity score. It's quite computationally expensive, so not a good idea to use across all your documents, but OK for post-processing a limited set. We take our matched documents from the similarity search above and feed each one into a cross-encoder model, along with the query. The documents can then be re-ordered based on the cross-encoder similarity score, rather than the original encoding proximity score.
from sentence_transformers import CrossEncoder
model = CrossEncoder("BAAI/bge-reranker-base")
sentences = [[query, doc.page_content] for doc in results]
scores = model.predict(sentences)
reranked = [r[0] for r in sorted(zip(results, scores), key=lambda x: 1-x[1])]
for i, r in enumerate(reranked):
print(f'{i+1}) {r.page_content}')
1) found the golden retriever
2) Fritz the Golden Retriever
3) Retriever from California has
4) return of seven-year-old dog
5) Owner decided pet pooch
6) about the pet’s injuries.
7) Dog was discovered in play
8) dog was more important to
9) Dogs charity hailed the study
10) treats, a new study claims.
Reading data from other sources
In this example, we used simple unformatted text from a preprepared dataset. Data is often not this clean in real life and text can include formatting such as headings and tables. LangChain offers a range of loaders which can handle many different file formats and extract relevant documents, such as Word Documents, PDFs, and Markdown.
Summary
We have demonstrated how to search for text based on its meaning. We created embeddings of chunked article summaries and stored them in a vector database, then searched them using an embedded query. Finally, we looked at how to improve the ranking of results by using a cross-encoder. It's important to try out different chunking approaches on your own data and maybe some different embedding models to find out what works in your context. Semantic search is a powerful way of retrieving information from your data as it does not rely on exact matches. It can therefore help you find what you're looking for faster. It's highly efficient and can work well across large numbers of documents. Semantic search is a key part of Retrieval Augmented Generation (RAG) pipelines, which allow LLMs to answer questions based on your data.
Read more technical blogs from our expert Data Scientists.


